Подготовка данных для ИИ и машинного обучения: практическое руководство для продакшена
Подготовка данных для ML и AI –это многоступенчатый процесс: сбор информации из разных источников, ее разметка, очистка и повышение качества, чтобы получить хорошо откалиброванный, корректно размеченный и непредвзятый датасет для обучения модели.
Это не разовое действие, а непрерывный процесс: каждый раз, когда появляются новые данные, они требуют повторной проверки, очистки и разметки.
Зачем подготавливать данные для машинного обучения и ИИ?
Подготовка данных – самая трудоемкая часть любого ML-проекта и может занимать до 80% времени. Но вложение в качественное исследование данных окупается многократно.
Уверенность в данных
В эпоху ИИ старая формула “мусор на входе – мусор на выходе” трансформировалась в “мусор на входе – красиво оформленный мусор на выходе”. Если не уделить внимание качеству данных, можно получить модель, которая выглядит убедительно, но дает ложные выводы.
Высокоточная аналитика
Чистые, релевантные данным задачи и свободные от предвзятости наборы позволяют принимать взвешенные бизнес-решения.
Лучший пользовательский опыт
В конкурентных сферах – например, стриминговых платформах или e-commerce с ИИ-рекомендациями – качество данных напрямую влияет на пользовательский опыт и помогает компаниям привлекать и удерживать аудиторию.
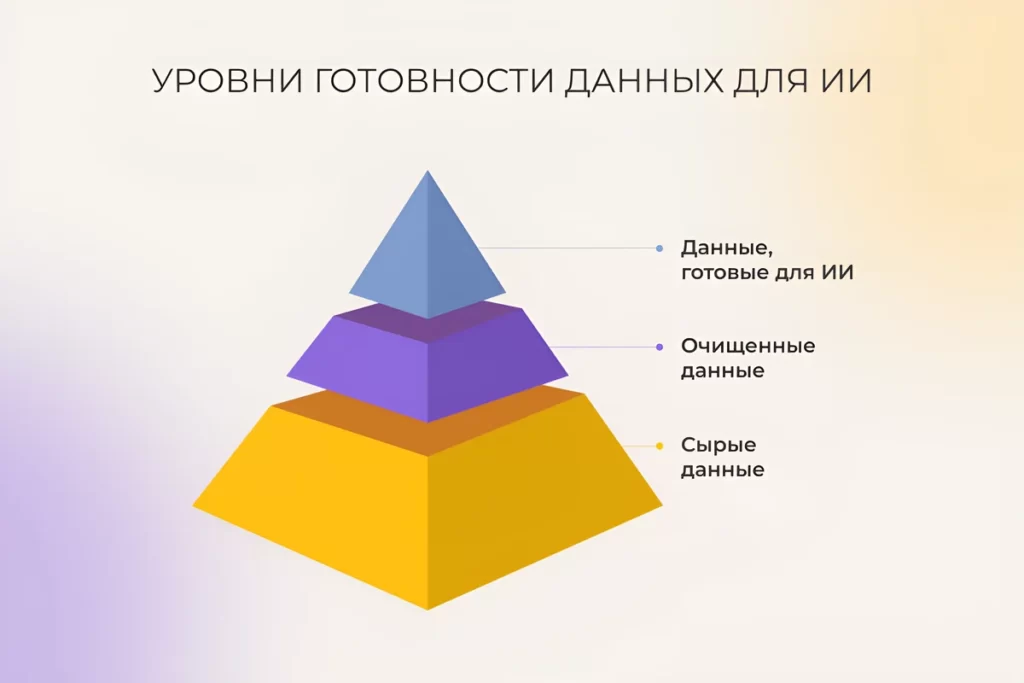
Уровни готовности данных для AI & ML
ML-модели хороши ровно настолько, насколько хороши данные, на которых они обучаются. Сырой, разнородный массив информации нужно привести к чистому, структурированному и задачно-ориентированному виду.
1. Сырой (raw) уровень
Необработанные данные в разных форматах, полученные из множества внутренних и внешних источников. Обычно хранятся в data lake или lakehouse. На этом этапе данные никак не проверены, содержат шум, дубли и ошибки.
2. Очишенные данные (clean data)
Структурированные данные, в которых удалены дубликаты, выбросы и пропущенные значения – то есть они пригодны для работы в разных проектах. Часто хранятся в data warehouse для удобного доступа, но они ещё не привязаны к конкретной ML-задаче.
3. Данные, готовые к ИИ (AI-ready)
Когда задача определена, специалисты получают очищенные и размеченные данные и проверяют, соответствуют ли они потребностям проекта. Например, они исключают нерелевантные данные – скажем, изображения собак из датасета для обнаружения безбилетников в транспорте.
Также на этом этапе определяют, нужно ли уменьшить датасет или, наоборот, дополнить его синтетическими данными.
Проверка датасета на наличие дублей и пропусков – это самый быстрый способ понять, насколько “сломаны” ваши данные. Например, можно воспользоваться Python-библиотеками Pandas и Great Expectations, чтобы автоматически выполнить такую проверку. Если точных дублей более 3% – убедительный признак того, что данные непригодны для обучения.
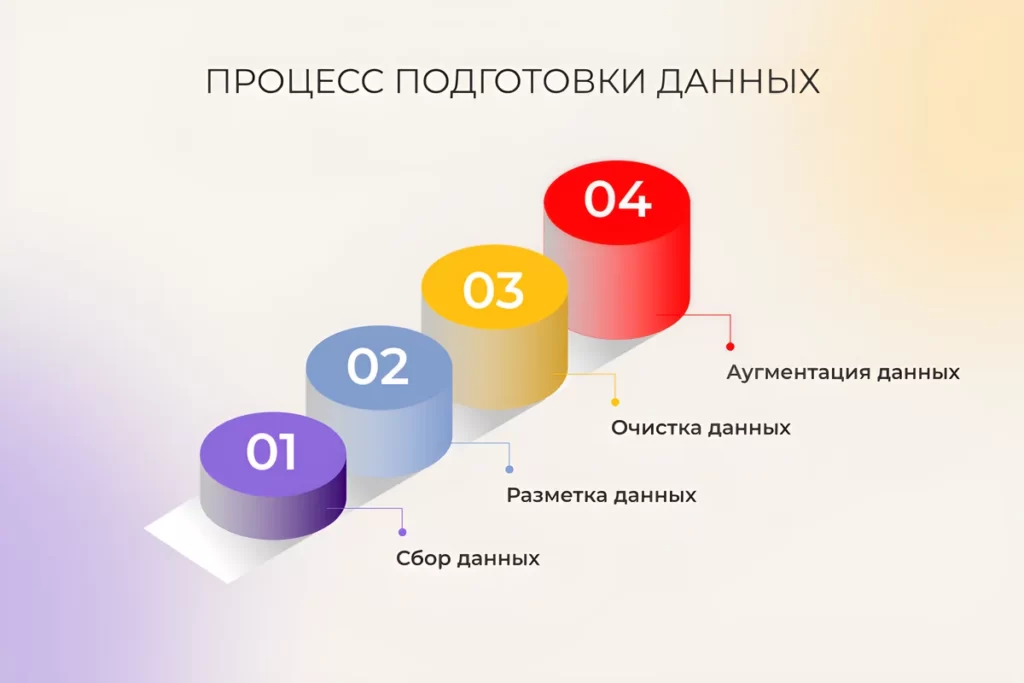
Как подготовить данные для машинного обучения и ИИ
За любой успешной AI-моделью стоит объёмная, рутинная и незаметная работа по подготовке данных. Вот проверенные на практике рекомендации, как сделать каждый этап максимально полезным.
1. Сбор данных
Первое, что нужно для грамотного сбора данных, – привлечь опытного специалиста по данным (data-scientist). Когда цель ML-проекта сформулирована, он определяет корректную стратегию сбора данных и помогает избежать попадания скрытой предвзятости в тренировочный датасет.
То же самое касается и “шума” в данных – его нужно фильтровать заранее.
Например, в задаче прогнозирования оттока пользователей, где данные приходят с сайта, CRM и рекламных платформ, важно заранее убрать шум: тестовые аккаунты, предпросмотры e-mail-кампаний, подозрительные клики или активность ботов-мониторингов.
В проектах с IoT-устройствами, физический мир буквально “прошит” в данные: вибрации, скачки температуры, электрошум. В одном из проектов в сфере нефтегаза вибрации буровых установок сильно осложняли выделение полезных сигналов – пришлось детально изучить данные датчиков, выделить наиболее информативные поля и снизить вес остальных, чтобы уменьшить их шумовое влияние.
Где собирать данные?
Внутренние источники:
- базы данных;
- операционные системы (ERP, CRM, складские системы и т.п.).
Внешние источники:
- публичные базы;
- соцсети;
- сторонние датасеты;
- открытые или покупные отчёты и статистика.
Важно позаботиться о линейности данных с самого начала их подготовки, когда можно проследить путь любой записи в датасете от источника до текущего состояния. Это упрощает исправление ошибок и аудит.
2. Разметка данных
После сбора сырые данные необходимо “объяснить” модели – разметить их. Метки помогают модели интерпретировать информацию и обеспечивают точность результатов.
Хотя разметку можно автоматизировать, наш опыт показывает: если вы хотите, чтобы ML-модель действительно приближалась к человеческому восприятию, мышлению и оценке, часть разметки должна выполняться людьми.
Как эффективно использовать гибридный подход, не разорившись:
Создайте “золотой” seed-набор
Пусть три разметчика независимо разметят 5-10% датасета (в зависимости от размера). Используйте короткое руководство, измерьте согласованность разметчиков, устраните расхождения. Нужны не senior-специалисты – достаточно обученных аннотаторов.
Обучите автолейблер и запустите цикл
Используйте золотой набор для обучения инструмента полуавтоматической разметки (passive learning), автоматически разметьте остальные данные и выборочно проверяйте качество. Неуверенные примеры возвращайте людям (active learning), пока качество не стабилизируется.
Подберите инструменты
Подойдут open-source решения вроде CVAT или Label Studio, а также SaaS-платформы: SuperAnnotate, LabelBox и др.
Проведите финальную проверку
Аннотаторы из первого шага проверяют авторазметку, чтобы убедиться в стабильном и высоком качестве по всему датасету.
3. Очистка данных
Когда весь датасет размечен, нужно очистить его от дублей, выбросов, пропусков, нерелевантных или ошибочных записей. Можно использовать Pandas и Great Expectations для автоматического поиска проблем.
Иногда датасет намеренно нужно дополнить ошибочными и неконсистентными примерами. Это особенно актуально для диалоговых AI-чатботов: от поддержки клиентов до ассистентов по бронированию авиабилетов или финансовых помощников. Нужно учитывать запросы с опечатками, неправильной грамматикой и синтаксисом – это значительно улучшает точность распознавания намерений.
Дальнейшие решения – удалять ли выбросы, восстанавливать ли недостающие значения или корректировать их с привлечением доменных знаний – требуют участия человека.
Не торопитесь с анонимизацией!
Шифрование критически важно для защиты данных, но если применить его слишком рано – к “грязному” датасету – это затруднит поиск ошибок и нерелевантных записей. Лучший момент для анонимизации – после приведения датасета в порядок.
4. Аугментация данных
Если после очистки данных оказывается слишком мало для обучения модели (что может означать и десятки медицинских записей, и тысячи взаимодействий пользователей в e-commerce), помогает аугментация.
Например, дерматологическая исследовательская лаборатория разрабатывает ИИ-ПО для предварительной диагностики кожи по фото. Для редкого заболевания, такого как кожная Т-клеточная лимфома, ранние признаки могут быть похожи на экзему или псориаз, и примеров почти нет. Тогда специалист по данным может использовать аугментацию изображений (зум, отражение, поворот, обрезка, небольшие изменения освещения), чтобы расширить датасет.
В менее регулируемых областях можно использовать синтетические данные, чтобы расширить датасет.
Если у вас всё ещё остаются вопросы по подготовке данных, стоит обратиться к провайдеру услуг по консалтингу в области ИИ и машинного обучения.
Чеклист по подготовке данных для AI/ML
Краткое резюме шагов, которые помогают избежать переделок. Выполните это до начала моделирования:
- Подключите специалиста по данным на раннем этапе, чтобы он разработал стратегию сбора данных, отфильтровал шум и предотвратил появление скрытой предвзятости.
- Используйте гибридный подход к разметке: “золотой” набор → авторазметчик → выборочная проверка записей с низкой уверенностью.
- Автоматизируйте первый этап очистки данных, затем подключите экспертов, чтобы удалить, восстановить или исправить данные на основе доменных знаний.
- Анонимизируйте чувствительные данные после разметки и очистки.
- Применяйте аугментацию, если после предыдущих шагов датасет оказался слишком маленьким.
Подготовка данных – это основная работа, которая ускоряет каждый следующий шаг
Подготовка данных похожа на подготовку почвы перед посадкой. Если в земле много камней и сорняков, ничего не вырастет. То же самое и с ИИ: чистые, сбалансированные и лишённые предвзятости данные дают модели плодородную основу для качественной работы.